Theory vs. Practice
Diagnosis is not the end, but the beginning of practice.
› What makes an expert "cheat"?
Once again, I was sent a link and asked to explain a test where "G-WAN is slower than XYZ". This time, mere amateurism is not a valid excuse because this young guy is:
- Senior Engineer at Oracle;
- Organization Admin and Mentor at Google Summer of Code;
- Project Leader of a 11-year old Web server (by comparison, G-WAN is 3 years old).
The remarkable feat here is that this expert has not spared his efforts to extract... 2,500 requests per second from G-WAN, letting him claim that his server is "12% faster than G-WAN".
This must be compared to an older test made in 2011 by an academic expert on a slower machine (an i3 CPU instead of an i5), with a slow single-thread client test tool (AB) and an older G-WAN version that delivered... 142,000 requests per second.
That's a factor 56 difference. If you take the CPU into account, that's a factor 100 difference. Let's see how such an error of this magnitude is possible for an expert, what expert is wrong – and why an expert can be ready to compromize his reputation that far.
How high is the floor?
The least powerful (modern) CPU that has been tested by an independent G-WAN user is an Intel Atom CPU N570 @ 1.66GHz. This test is far from optimal because:
- the system TCP/IP stack was not tuned;
- the weigttp client tool was used with 4 threads (instead of 2, like the tested dual-Core CPU).
But if our goal is to identify how modest can be G-WAN's performance on a low-consumption dual-Core CPU, then this test can certainly be used as an helpful independent non-optimal reference – exactely what we can expect from a comparison made by a competitor.
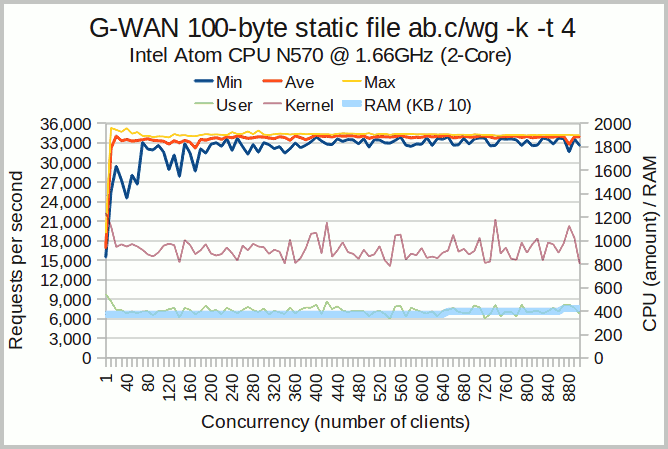
Intel Atom Chart
We do not have comparative Atom tests for other servers, but G-WAN's memory usage of 4 MB as well as the performance (30k+ RPS) and scalability are quite good (both are stable on the [1-1,000] concurrency range).
This Atom is 5.7x less powerful than the ORACLE engineer's CPU.
Nevertheless the Atom was capable to serve more than 35k RPS – 14x more than the 2.5k RPS what were announced by the ORACLE engineer.
Where is the bias? Let's take another independent test.
Examining the facts
The US-based user who signaled this test made by an ORACLE expert has made an ab.c test comparing these two HTTP servers. And his CPU is much less powerful than the CPU used by the ORACLE expert:
- Intel Xeon W3680 @ 3.33GHz (6 Cores) ............ 10,056 @ PassMark performance test (G-WAN's usually tested CPU)
- Intel Core i5-2520M @ 2.50GHz (4 Cores) ........... 3,619 @ PassMark performance test (the ORACLE expert's CPU)
- Intel Core2 Duo E6750 @ 2.66GHz (2 Cores) ...... 1,675 @ PassMark performance test (the G-WAN user's CPU)
- Intel Atom CPU N570 @ 1.66GHz (2 Cores) ........... 638 @ PassMark performance test (the low-consumption CPU)
With a CPU more than twice as fast, the HTTP server of the ORACLE expert should shine, right?
Well, not really:
With G-WAN, the modest Core2 Duo CPU is processing 170,869 RPS. Well, that's quite better than the ORACLE expert's "best-effort" that miserably produced 2,500 RPS (on a twice more powerful i5 4-Core CPU).
Note: The difference (170k vs 142k requests/second) as compared to the older test made in 2011 with an i3 CPU comes from weighttp (faster and more scalable than the single-threaded AB), and from more recent versions of Linux and G-WAN.
This independent ab.c test shows that, on a tiny Core2 Duo CPU, G-WAN is 4 times faster (twice the requests in half the time), twice scalable (the slope is twice as flat) and uses more than twice less CPU and RAM resources than the alleged "12% faster" ORACLE expert's server called 'Monkey' (sic):
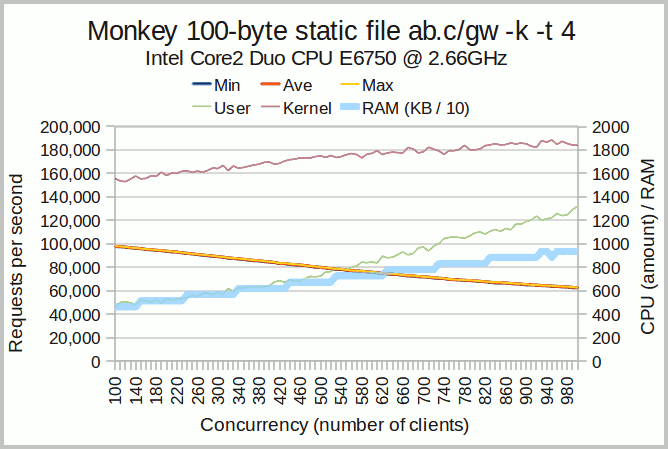
Monkey Chart Interpretation
Monkey's scalability is following a RPS (requests per second) slope correlated with the quickly growing CPU usage (both kernel and user-mode but with an obvious user-mode overhead).
This 'Monkey' user-mode overhead is due to a poor design and implementation of the server application.
A characteristic that can be verified in other aspects like the too fast growing memory usage, or the fact that the min / average / max curves are merged – at this low level of performance that's a clear sign that the implementation is sub-optimal.
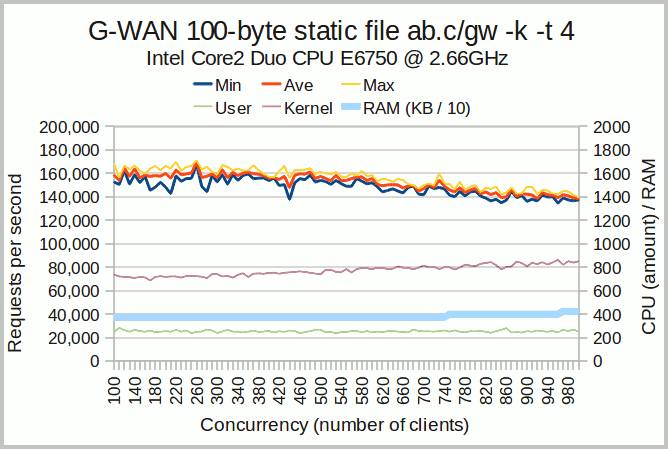
G-WAN Chart Interpretation
G-WAN's scalability is also following a RPS slope correlated with the very slowly growing kernel CPU usage (in contrast with Monkey, G-WAN's user-mode CPU usage is not growing with concurrency).
This constant and very low user-mode overhead lets G-WAN scale vertically as concurrency is growing.
As opposed to Monkey, with G-WAN, the kernel is using CPU resources faster than G-WAN's user-mode CPU usage. As a result, the Linux kernel is the bottleneck far before G-WAN.
This is what lets G-WAN serve twice the requests in half the time and scale so much better while using less hardware resources:
server top requests/sec @ concurrency RAM CPU Avg RPS total elapsed time -------- ------------------------------ ------- ------- ------- -------------------- G-WAN 170,869 req/sec @ 260 clients4.15 MB 279,423 142,071 00:31:40 (hh:mm:ss) Monkey 98,035 req/sec @ 100 clients 9.16 MB 696,813 71,823 01:00:30 (hh:mm:ss)
So, is this ORACLE expert's server really faster?
The servers comparison detailled above is immensely more informative than the poorly designed test published by this ORACLE expert because here you can easily identify WHAT makes G-WAN's architecture and implementation faster and more scalable.
If Monkey's author used such a poorly designed test while he had read the public domain ab.c G-WAN benchmark – that's obviously for a reason: to hidde the facts, to prevent people from getting the insight, the ability to judge by themselves, and to keep them behaving as docile users buying the wrong solutions.
Today's development version of G-WAN processes an additional 100k requests per second on a 6-Core CPU (so the new next publicly released version will be both faster and more scalable... while delivering many new features usually packaged as separate products). This is all about bringing tangible value with higher performance and lower costs involved in unecessary hardware (the value denied by the ORACLE expert) as well as about simplifying our day-to-day life with much easier to use, better designed products.
ORACLE expert's receipe for good cooking
All the experts will tell you that, if you want to demonstrate something to non-experts (the category unable to spot obvious irrelevancies), then selecting the right ingredients will lead you where you want to be.
So, let's start with that. This is relatively simple to achieve since you will have to select the extreme opposite of the best available recommendations to build a relevant HTTP server benchmark:
- use the ridiculously slow siege client test tool (instead of the fast SMP weighttp program)
- disable HTTP Keep-Alives (so you will test the TCP/IP stack rather than the server application)
- use one single unconstant test shot (instead many rounds to have a relevant min/average/max range)
- use one single concurrency (instead of the whole [1-1,000] concurrency range to see how servers behave)
- use a 200 KB binary file to test the Linux kernel (instead of a 100-byte HTML file to test the HTTP server)
If you do all the above, you will be assured to test everything but the user-mode server application that you are supposed to benchmark – this will let you pick the best ingredients that match what you want to demonstrate.
But you will also be able to do several such flawed tests to pick the results that best matches your goals (your server ranking high and another more capable server being humbled).
And, if this is not enough to make the point, given the amount of cheating already involved, you can as well create your own numbers: the non-experts will never suspect anything.
That's all the value of skipping the good practices and the most capable test tools made available by less creative experts in the blatant cooking area.
Why would an expert make a factor 100 mistake?
Is it more credible to state that while Eduardo has been working on Monkey for 11 years, he was:
- not curious enough to make any serious test before issuing the false claim that his server "is faster than G-WAN"? or,
- not willing to publish the results of the more relevant ab.c public-domain test published with G-WAN since 2009?
In contrast to the commented charts published above:
Eduardo's test shows only 1 single value of 1 of the 6 curves (Min/Ave/Max/User/Kernel/RAM) rendered for each server's chart.
This alone should give a clue about how far G-WAN is built on real-life insights rather than just on clueless bragging.
If that was the first time (and not a growing trend), or if that was a rookie engineer (rather than a Senior) and if that was a startup (rather than ORACLE) then this kind of "error" ranging in the several orders of magnitude could be ranked as "accidental".
But when 'errors' are (a) recurring, (b) never acknowledged and (c) never corrected then you can safely call it a 'strategy'.
This example illustrates that some tests can be at the same time documented and irrelevant – when an expert decides to put his experience at work to deceive the non-experts.
All it requires is a decent incentive. Say, like a job at a prominent industry player who markets notoriously slow server technologies. The fact that this same company is manufacturing hardware is probably accidental: after all, fast software just kills hardware sales, so why bother?
UPDATE: Monkey relying on more F.U.D. to cover-up its initial F.U.D.
Unlike for his previous test posted silently, this time, Eduardo emailed me about his new post, refining his claim by stating that his server is "faster than GWan under certain conditions" (sic).
Eduardo now claims that his benchmark criteria (and execution) are more fair than G-WAN's because, he says:
- "HTTP keep-alives are irrelevant" (say good-bye to AJAX, Comet, online Games, Big Data, HPC, HF Trading, etc.)
Google is pushing pipelined requests with SPEEDY to speed-up the Web. Firefox is also pushing for pipelined requests to reduce latency and server overhead due to TCP/IP handshaking... done in the kernel. Eduardo claims that "HTTP keep-alives are irrelevant" just because he needs the kernel to be tested as the bottleneck – instead of testing the user-mode server appplications.
- "Small static files are irrelevant" (say good-bye to AJAX, Comet, online Games, Big Data, HPC, HF Trading, etc.)
The Web 1.0 was about flat bloated static files. The Web 2.0 is about JSON, AJAX and Comet or streaming, and we are not even talking about High-Frequency Trading, HPC Message-Passing, etc. Here again, Eduardo claims that "small static files are irrelevant" because he needs the kernel to be tested as the bottleneck – instead of testing the user-mode server appplications.
- "GWan has to fix its design" (hence a bigger RAM and CPU usage, claims Eduardo)
sendfile() was accidentally disabled in this specific G-WAN development version chosen by Eduardo. Since Eduardo is following G-WAN for years – and since he published his first comparative test relying entierely on sendfile(), there is little wonder about the timing. Eduardo has picked this specific version of G-WAN just because that allowed him to compare Monkey using sendfile() doing the job in the kernel against G-WAN's user-mode read()/write() implementation.
As this ORACLE expert is (clearly) not targeting the most technically skilled among us, let's quote an independent technical reference.
The Linux man page explains why sendfile() is faster and uses less CPU and RAM resources than read() and write():
$ man sendfile "Because this copying is done within the kernel, sendfile() is more efficient than the combination of read(2) and write(2), which would require transferring data to and from user space".
This explains why, with the 200 KB static file used by Eduardo, this version of G-WAN was using more RAM and kernel CPU than in any previous version where sendfile() was not accidentally disabled. Eduardo did not miss this unique opportunity (since year 2009) to publish hist first G-WAN benchmark.
Note that, even in Eduardo's test, and despite using read() and write() instead of sendfile(), G-WAN was still using less user-mode CPU resources than Monkey – proof of a better design and implementation – even under this utmost unfavorable case.
Let's wait for the new G-WAN version re-enabling sendfile(), making room for a so-called "fair big static file server comparison" despite the fact that this particular job is entirely performed by the... Linux kernel (rather than in the user-mode server applications supposed to be compared).
Let's hope that Monkey will fix its far too low user-mode performance/scalability and its far too high CPU and RAM user-mode resource usage, as revealed in the above charts using HTTP keep-alives and a small static file – all of which are processed in the user-mode server applications that were really compared here... because this is relevant.